Publications
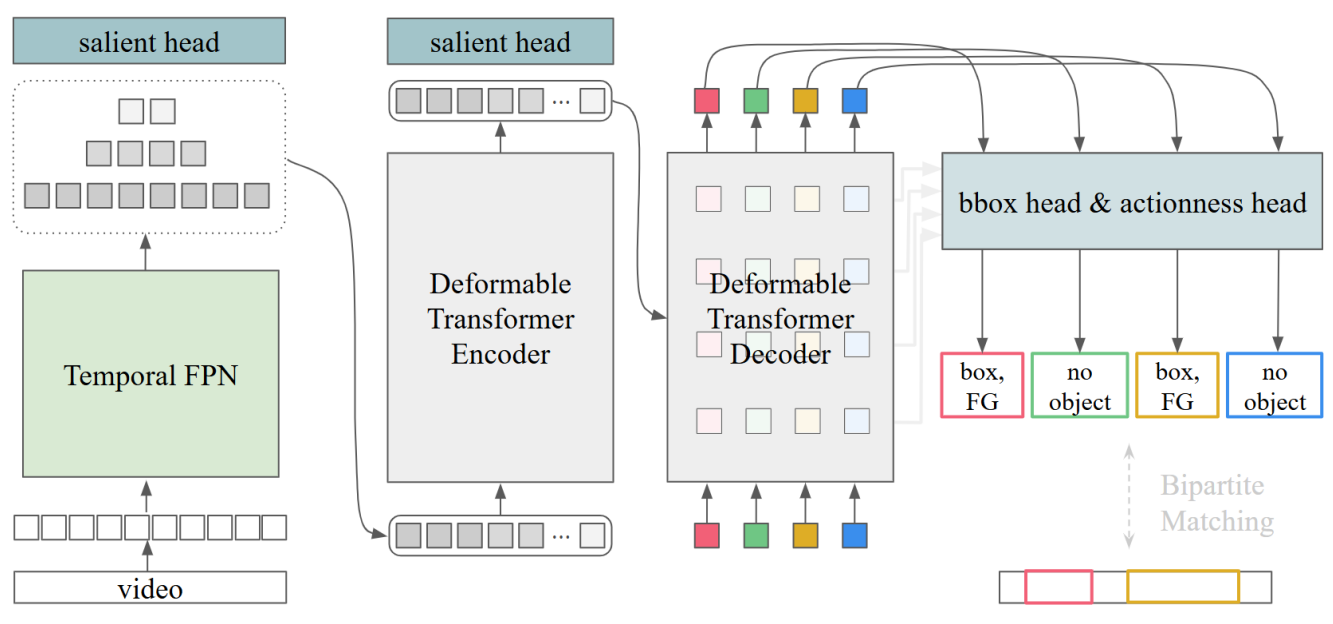 |
TP²-DETR: Unlocking Deformable DETR for Zero-Shot Temporal Action Proposal Generation with Temporal Feature Pyramids (Ya-Yun Cheng, Kan Tippayamontri, Chih-Yuan Yang, and Jane Yung-jen Hsu), CVPR26 Findings Track paper supp |
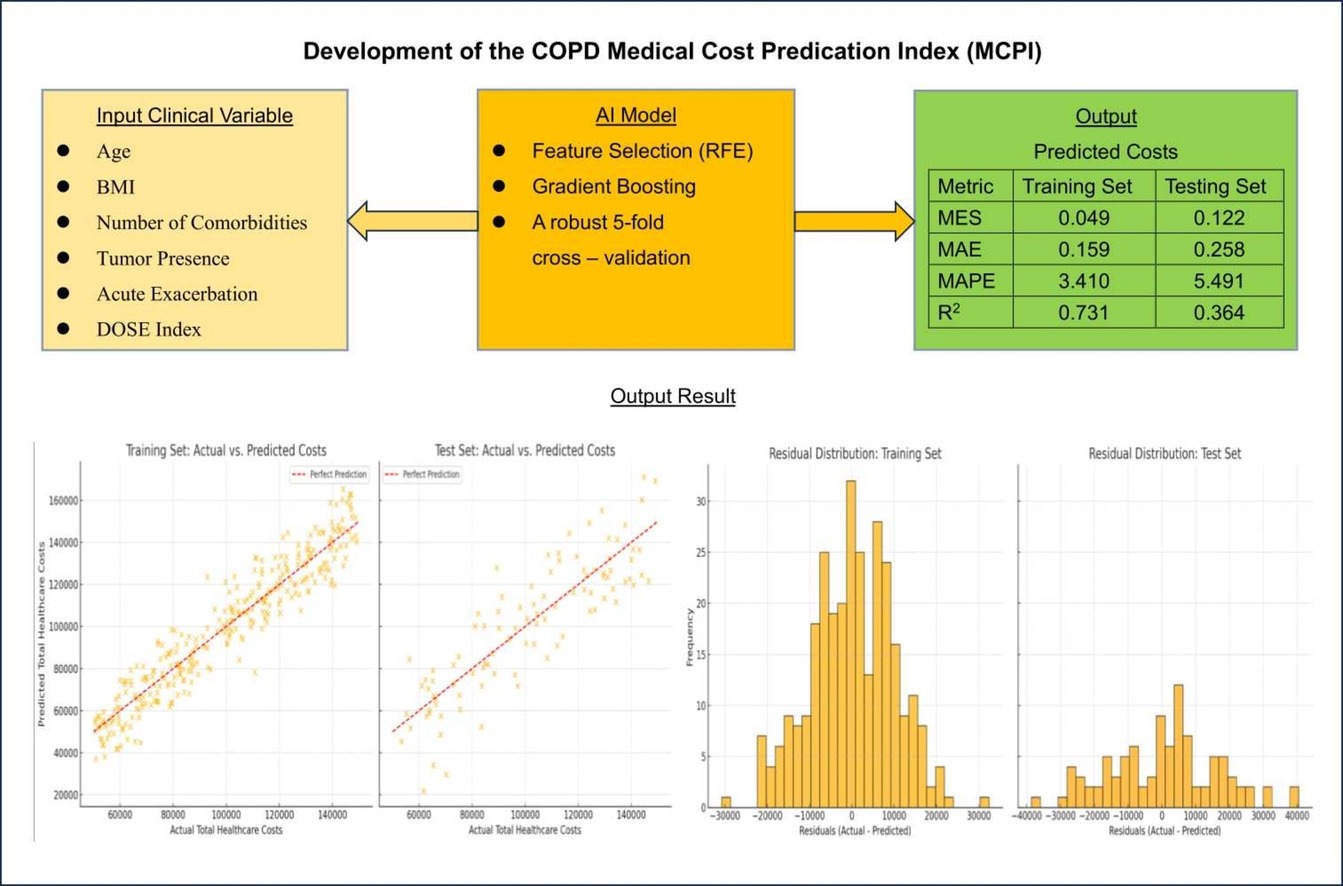 |
Development and Validation of a Novel AI-Derived Index for Predicting COPD Medical Costs in Clinical Practice (Guan-Heng Liu, Chin-Ling Li, Chih-Yuan Yang, and Shih-Feng Liu), Computational and Structural Biotechnology Journal 20250201 Vol.27. paper |
 |
SA-DVAE: Improving Zero-Shot Skeleton-Based Action Recognition by Disentangled Variational Autoencoders (Sheng-Wei Li, Zi-Xiang Wei, Wei-Jie Chen, Yi-Hsin Yu, Chih-Yuan Yang, and Jane Yung-jen Hsu), ECCV24. paper supp code |
 |
Object Relation Attention for Image Paragraph Captioning (Li-Chuan Yang, Chih-Yuan Yang, and Jane Yung-jen Hsu), AAAI21. paper |
 |
CalliGAN: Style and Structure-aware Chinese Calligraphy Character Generator (Shan-Jean Wu, Chih-Yuan Yang, and Jane Yung-jen Hsu), CVPRW20. paper workshop |
 |
A Mobile Robot Generating Video Summaries of Seniors’ Indoor Activities (Chih-Yuan Yang, Heeseung Yun, Srenavis Varadaraj, and Jane Yung-jen Hsu), MobileHCI19. paper code |
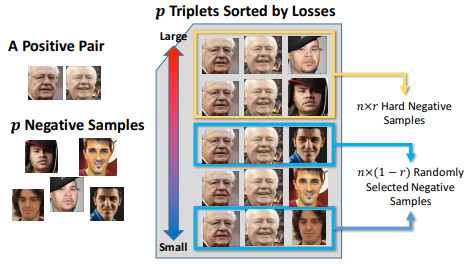 |
IdenNet: Identity-Aware Facial Action Unit Detection (Cheng-Hao Tu, Chih-Yuan Yang, and Jane Yung-jen Hsu), FG19. paper |
 |
SemiStar-GAN: Semi-Supervised Generative Adversarial Networks for Multi-Domain Image-to-Image Translation (Shu-Yu Hsu, Chih-Yuan Yang, Chi-Chia Huang, and Jane Yung-jen Hsu), ACCV18. paper |
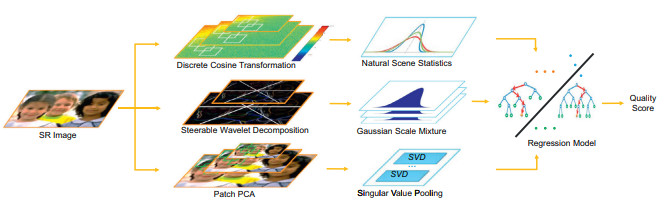 |
Learning a No-Reference Quality Metric for Single-Image Super-Resolution (Chao Ma, Chih-Yuan Yang, Xiaokang Yang, and Ming-Hsuan Yang), CVIU17. paper |
 |
Compressed Face Hallucination (Chih-Yuan Yang, Sifei Liu, and Ming-Hsuan Yang), IJCV17. paper |
 |
Single-Image Super-Resolution: A Benchmark (Chih-Yuan Yang, Chao Ma, and Ming-Hsuan Yang), ECCV14. paper |
 |
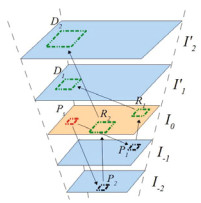
Fast Direct Super-Resolution by Simple Functions (Chih-Yuan Yang and Ming-Hsuan Yang), ICCV13. paper |
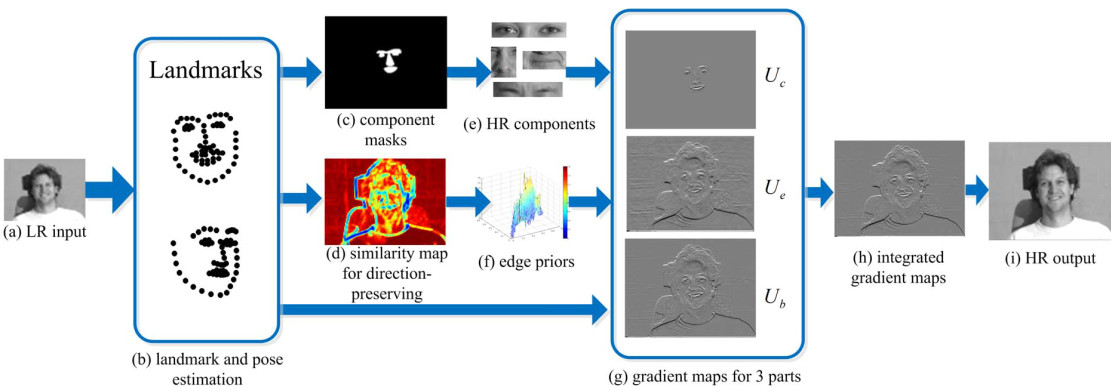 |
Structured Face Hallucination (Chih-Yuan Yang, Sifei Liu, and Ming-Hsuan Yang), CVPR13. paper |
 |
Exploiting Self-Similarities for Single Frame Super-Resolution (Chih-Yuan Yang, Jia-Bing Huang, and Ming-Hsuan Yang), ACCV10. paper |
Thesis writing checklist
Check out my thesis writing checklist for tips on writing a thesis.